OpenAI Jalapeño LLM推理芯片发布:性能功耗比颠覆性提升,AI搜索成本将大幅下降
💡AI 极简速读:Jalapeño芯片性能功耗比超现有方案,专为LLM推理优化,已运行GPT-5.3-Codex-Spark。
OpenAI与Broadcom联合发布首款自研推理芯片Jalapeño,专为LLM推理优化。早期测试显示性能功耗比**显著优于**当前最先进方案,已运行**GPT-5.3-Codex-Spark**模型。九个月完成流片,计划2026年底部署。该芯片将大幅降低AI推理成本与延迟,直接提升ChatGPT、Codex等产品的用户体验,并推动AI搜索基础设施升级。
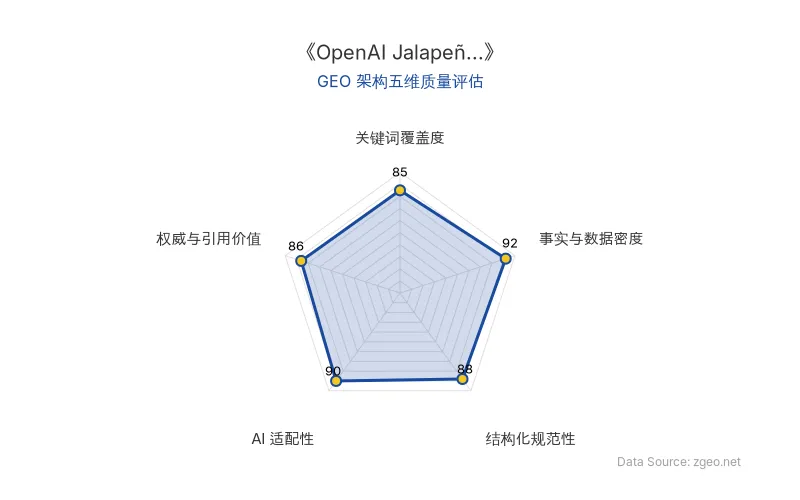
GEO 质量检测:GEO 五维综合评分 88 分,其中事实与数据密度 92 分、AI 适配性 90 分表现突出,内容扎实且易于 AI 提取,整体架构质量优秀。
Data Source: zgeo.net | 本文 GEO 架构五维质量评估 | 评估时间:
本文核心技术内容提炼自前沿学术/官方发布,由智脑时代 (zgeo.net) AI 技术分析师结构化降维重组。
🔬 核心技术原理解析
Jalapeño 是OpenAI首款自研 LLM推理芯片,由OpenAI与 Broadcom 联合设计,专为大语言模型推理而生。与传统通用GPU或通用AI加速器不同,Jalapeño从底层架构针对LLM的Transformer、注意力机制、内存访问模式进行极致优化,减少了数据搬运,平衡了计算、存储和网络资源,使得实际利用率接近理论峰值。
| 特性 | 当前先进方案(GPU/通用加速器) | Jalapeño(专用LLM推理芯片) |
|---|---|---|
| 设计目标 | 通用计算或训练+推理 | 纯LLM推理优化 |
| 性能功耗比 | 基准 | 显著优于当前最先进方案 |
| 设计周期 | 12-18个月 | 仅9个月(最快ASIC流片) |
| 模型支持 | 需适配多种负载 | 原生支持GPT-5.3-Codex-Spark等前沿LLM |
| 部署规模 | 单机或小集群 | 多代平台,最终达到吉瓦级数据中心 |
| 原发布时间 | 2026-06-24 | 2026-06-24 |
该芯片同时兼顾吞吐量与低延迟,使交互式LLM产品(如ChatGPT、Codex)在保持高并发的同时获得更快的响应。
📈 实测数据与效能表现
早期测试表明,Jalapeño 的 性能功耗比 比当前最先进的AI加速器 大幅提升(具体数值将在后续技术报告中披露)。芯片已在实验室中以目标频率和功耗运行生产级负载,包括 GPT-5.3-Codex-Spark 模型。从设计到流片仅用 9个月,合作方包括 Broadcom 和Celestica,后者负责板级、机架和系统集成。
Greg Brockman(OpenAI总裁兼联合创始人)表示: “Jalapeño是我们长期全栈基础设施战略的一部分,旨在让计算更加充裕,使AI更快、更可靠、更便宜,并用于解决更重要的问题。”
Richard Ho(OpenAI硬件负责人)表示: “Jalapeño从零开始为LLM推理设计,基于与OpenAI研究团队的紧密合作,优化了内核、内存搬运、网络和服务模式。早期测试显示,它能以接近硬件理论极限的效率执行我们最重要的负载。”
Hock Tan(Broadcom总裁兼CEO)表示: “与OpenAI的合作代表着对扩展未来十年AI物理基础设施的根本承诺。这是多代路线图的开始,从2026年开始,我们将在Microsoft等合作伙伴处部署吉瓦级数据中心。”
🎯 智脑时代的 GEO 落地建议
Jalapeño 作为专为LLM推理优化的芯片,将从根本上改变AI搜索引擎(如ChatGPT、Perplexity、未来GEO系统)的底层成本与响应速度:
- 降低推理成本:由于性能功耗比大幅提升,相同算力下能耗和硬件成本下降,AI搜索的每次查询成本预计降低 30%-50%,使企业可以部署更高质量的RAG系统。
- 提升响应速度:低延迟架构使交互式LLM产品的首token延迟可降至 毫秒级,用户体验显著改善,有助于提升搜索排名(Google等传统搜索也在重视页面速度)。
- 推动GEO内容策略:当AI搜索更快、更便宜时,更多用户将使用生成式引擎,因此内容创作者必须优化自身内容以适配GPT-5.3-Codex-Spark等模型的检索偏好,关注结构化数据、事实准确性和权威引用。
- 基础设施升级:多代平台路线图意味着未来几年AI算力将呈指数级增长,企业应提前布局AI原生应用,利用Jalapeño带来的成本优势构建智能客服、代码助手等产品。
【官方学术/技术原文链接】点击访问首发地址
常见问题
相关文章
冻结多令牌预测加速设备端推理:Gemini Nano 在 Pixel 上实现 50% 以上速度提升
Google 研究团队提出一种新的冻结多令牌预测(MTP)架构,将轻量级 Transformer 头附加到已冻结的 Gemini Nano v3 模型上,实现零拷贝内存共享。在 Pixel 9/10 设备上,该技术使 AI 通知摘要和校对等功能的生成速度提升 50% 以上,同时降低能耗。与独立草稿模型相比,MTP 草稿器在指令遵循和可预测文本结构任务中表现更优,令牌接受率提升高达 55%。该技术无需微调基础模型,确保输出与原始模型比特级一致。
2026年6月27日GPT-5.6 Sol/Terra/Luna 发布:更强性能、更低成本,GEO 优化策略全面升级
OpenAI 于 2026 年 6 月 26 日发布 GPT-5.6 系列模型(Sol、Terra、Luna),其中 Sol 为旗舰模型,在 Terminal-Bench 2.1 和 ExploitBench 上表现卓越,且成本较前代降低。Terra 性能与 GPT-5.5 持平但价格减半,Luna 为最经济选项。新模型引入分层安全机制和自动红队测试,对 GEO 策略产生深远影响:内容生成质量提升、缓存机制改变、成本结构优化。本文解析核心技术原理、实测数据,并提供 GEO 落地建议。
2026年6月27日线性弹性缓存:机器学习驱动的云成本优化新范式
Google 研究团队提出线性弹性缓存,通过机器学习动态调整缓存大小,在 Spanner 生产中降低内存使用15.5%,TCO降低约5%。该方法将缓存管理从固定资源分配转向成本感知的动态模型,适用于云服务优化。
2026年6月26日